義烏市全有日用百貨商行 一元二元商品,點亮日常便利生活

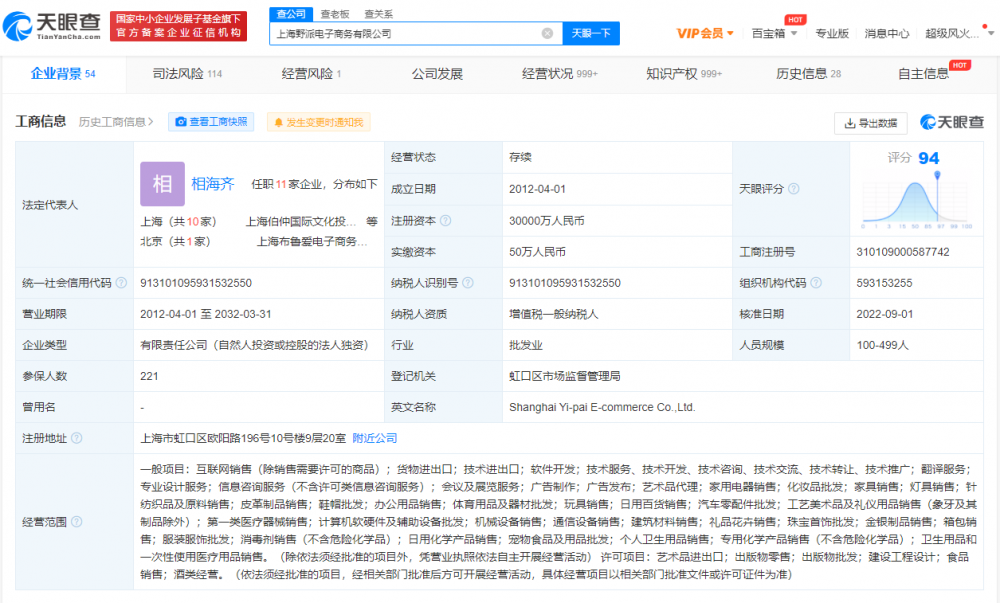
義烏市全有日用百貨商行是一家專注于日用百貨銷售的本地企業,以優質的服務和實惠的價格贏得了廣大消費者的信賴。商行主營一元商品和二元商品,致力于為顧客提供高性價比的日常必需品。從廚房用品到家居小物,從文具玩具到個人護理品,這里的商品種類豐富多樣,覆蓋了日常生活的方方面面。
一元商品區域匯集了各種小巧實用的物品,如鑰匙扣、小飾品、簡易工具等,價格僅為一元,滿足消費者對小件商品的即時需求。二元商品則提供更多選擇,包括塑料制品、清潔用品、文具等,雖價格低廉,但質量可靠,確保物超所值。
商行的經營理念是‘品質優先,服務貼心’,所有商品均經過嚴格篩選,確保安全環保。同時,商行注重客戶體驗,提供便捷的購物環境和友好的售后服務,讓每位顧客都能感受到購物的樂趣與便利。無論是家庭采購還是批發需求,義烏市全有日用百貨商行都能成為您的理想之選。歡迎前來選購,體驗一站式購物帶來的驚喜!
如若轉載,請注明出處:http://www.jonfong.cn/product/26.html
更新時間:2026-06-19 02:40:09